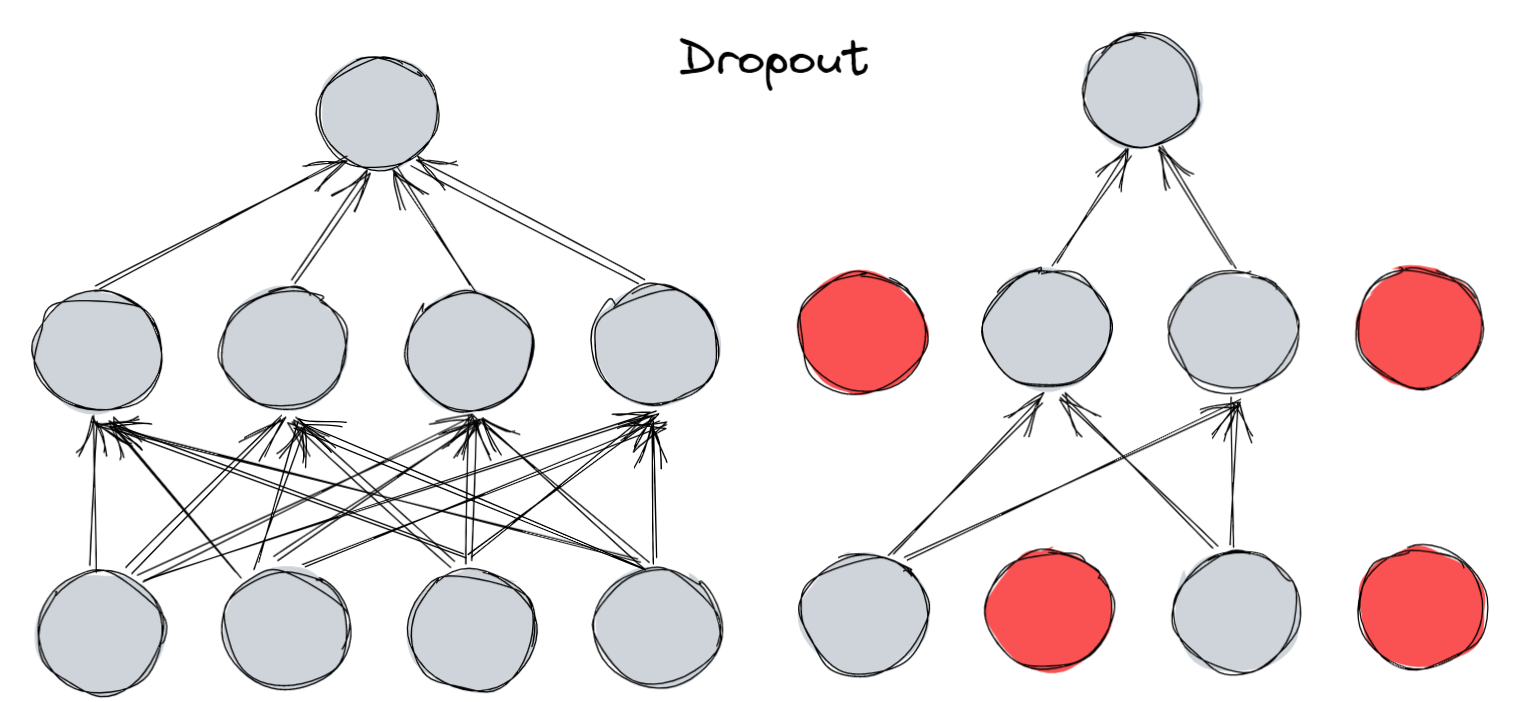
Dropout
Overfitting in NN
- layer 마다 L1, L2 regularization을 적용함
- 그러나 이것으로는 부족하다!
co-adaptation
- 일부 노드들이 서로 상쇄되면서 아무 일도 안해버림
- 즉 일부 뉴런들이 의존적으로 변해버림
- 노드의 낭비와 컴퓨팅 파워, 메모리 낭비를 야기함
dropout
- 이를 풀기 위한 새로운 regularization
- 하나의 모델이 다른 여러 모델을 시뮬레이션 하는 결과
Dropout
![]()
- z∼Bern(p)
hi(l+1)=σ(wi(l+1)⊤(hl⊙zl+bi(l+1))) - 0이 곱해지면 노드는 죽어버림
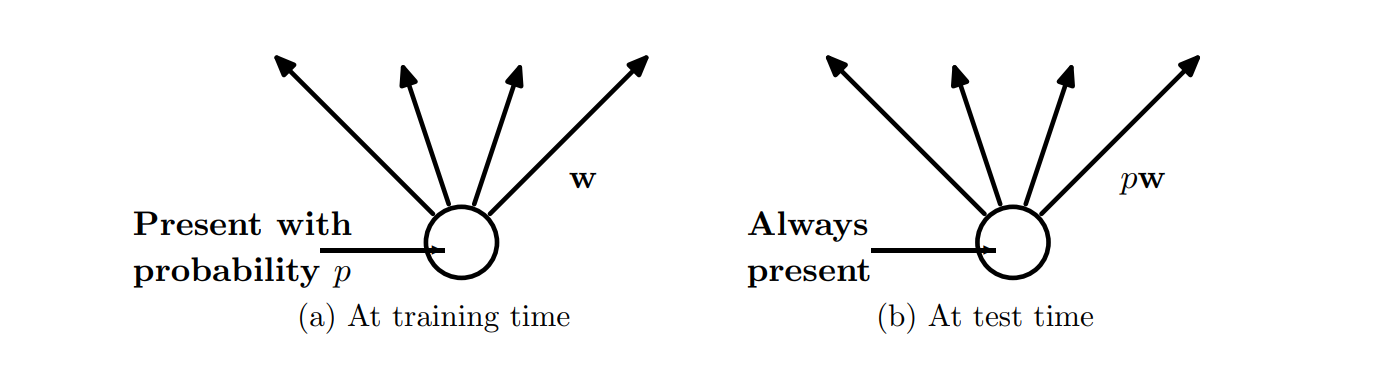
scale down
![]()
- 두번째 논문 3페이지 참고
- 훈련 시와 테스트 시 노드 수의 차원이 다른 문제가 있다.
- 테스트 시에는 drop training을 할 때 사용한 p 값을 가중치에 곱해서 사용한다.
Understanding dropout
EN=21(y−j∑pjwjxj)2
ED=21(y−j∑zjwjxj)2
∂wi∂ED=−yzixi+wizi2xi2+j=i∑wjzjzixjxi
∂wi∂EN=−ypixi+wipi2xi2+j=i∑wjpjpixjxi
E[∂wi∂ED]=−ypixi+wipi2xi2+wivar(zi)xi2+j=i∑wjpjpixjxi
=∂wi∂ENwipi2xi2+wivar(zi)xi2
=∂wi∂ENwipi2xi2+wipi(1−pi)xi2
- 이 식은 regularized network를 최소화한 것과 같다.
ER=21(y−j∑pjwjxj)2+21j∑pi(1−pi)wj2xi2
Inverted Dropout
- train 에서 dropout을 하고 가중치에 rescale을 진행함
wi(i)=wi(i)/ p - 즉 test에서 scale하지 않음
etc