
Chain Replication for Supporting High Throughput and Availability
https://pdos.csail.mit.edu/6.824/papers/cr-osdi04.pdf
1. Intro
- One challenge when building a large scale storage service is maintaining “high availability” and “high throughput”
- despite failures and concomitant changes to the storage service’s configuration
- Consistency guarantees also can be crucial but …
- large-scale storage service are not incompatible with high throughput and availability.
- ex) GFS declined to support strong consistency
- new chain replication
- coordinating fail-stop servers
- simultaneously supports high throughput, availability, and strong consistency.
2. Storage service interface

- T1 : pending
- T2 : ignore
- T3 : processing
- $\text{Hist}_{objID}$ : updates that have been performed on objID
- $\text{Pending}_{objID}$ : a set of unprocessed requests
3. Chain Replication Protocol
- Server assumed to be fail-stop
- each server halts in response to a failure rather than making erroneous state transitions.
- 잘못된 상태가 아닌 실패에 대한 응답으로 정지함
- server’s halted state can be detected by the environment.
- each server halts in response to a failure rather than making erroneous state transitions.
- With an object replicated on t servers, as many as t - 1 of the servers can fail
- without compromising the object’s availability
So we assume that at most t - 1 of the servers replicating an object fail concurrently
- Server composition
- Reply Generation : All replies are generated and sent by the TAIL
- Query Processing : Each query request is directed to the TAIL, processed atomically
- Update Processing : Each update req is directed to the HEAD, processed atomically and forwarded along a reliable FIFO link to next server.
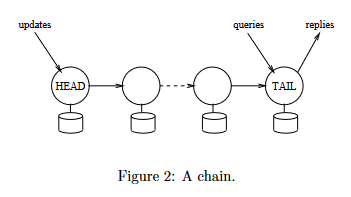
3.1 Protocol Details
- When chain replication is used to implement the Figure 1
- $\text{Hist}{objID} \rightarrow \text{Hist}^{T}{objID}$
- the value of $\text{Hist}$ stored by tail T
- $\text{Pending}_{objID}$ is set of client requests recieved by any server in the chain
- not yet processed by the taill
- $T1 = \text{ (i) Server in the chain receiving a req from a client}$
- $T3 = \text{ (ii) Tail processing a client request}$
- storage interface의 no-op, T1, 2, 3이 체인의 작동과 일치함을 보여 체인이 interface의 사양을 충족하는지 보임
- 두 $\text{i, ii}$ 만이 $\text{Hist, Pending}$에 영향을 미친다.
- 나머지 작동은 no-op와 동일
- $\text{Hist}{objID} \rightarrow \text{Hist}^{T}{objID}$
Coping with Server Failures
- master server
- detects failures of servers
- informs each server in the chain of ist new predecessor or new successor
- when the chain obatained by deleting the failed server.
- informs clients which server is the head and tail
- we assume master is single process and that never fail
- In practical
- replicates a master process
- In practical
Update Propagation Invariant
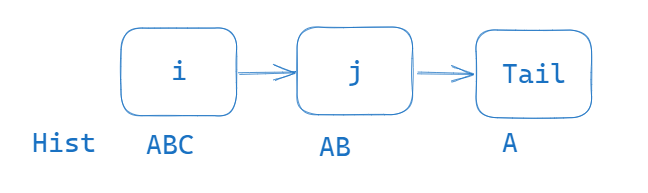
\(\text{Hist}^j_{objID} \le \text{Hist}^i_{objID}\)
- for server labeled i and j such that $i <= j$
- i is a predecessor of j in the chain
- $\text{Hist}^j_{objID}$ is prefix of $\text{Hist}^i_{objID}$ -
![]()
Failure of the Head
- Master removing H from the chain and making the successor to H the new head of the chain.
- Deleting server H from the chain has the effect of removing from Pending objID those requests received by H but not yet forwarded to a successor.
- is consistent with transition T2
Failure of the Tail
- remove tail T from the chain and making predecessor T− of T the new tail of the chain.
- consistent with repeated T3 transitions
- Peding decreases and Hist is increased
- commited 기준은 tail이다. T- 는 Hist가 더 크기에 증가 된다.
Failure of Othre servers
- Update Propagation Invariant is preserved
- $\text{Sent}_i$ : update requests that i has forwarded to some successor but that might not have been processed by the tail
- Whenever server i forwards an update request r to its successor, server i also appends r to $\text{Sent}_i$
- The tail sends an acknowledgement ack(r) to its predecessor when it completes the processing of update request r.
- And upon receipt ack(r), a server i deletes r from $\text{Sent}_i$ and forwards ack(r) to its predecessor.
Improcess Requests Invariant \(\text{Hist}^i_{objID} = \text{Hist}^j_{objID} \oplus \text{Sent}_i\)
- Thus, the Update Propagation Invariant will be maintained

Lecture note
chain (or p/b) versus Raft/Paxos/Zab (quorum)? p/b can tolerate N-1 of N failures, quorum only N/2 p/b simpler, maybe faster than quorum p/b requires separate CFG, quorum self-contained p/b must wait for reconfig after failure, quorum keeps going p/b slow if even one server slow, quorum tolerates temporary slow minority p/b CFG’s server failure detector hard to tune: any failed server stalls p/b, so want to declare failed quickly! but over-eager failure detector will waste time copying data to new server. quorum system handles short / unclear failures more gracefully
for a long time p/b (and chain) dominated data replication Paxos was viewed as too complex and slow for high-performance DBs recently quorum systems have been gaining ground due to good toleration of temporarily slow/flaky replicas
what if you have too much data to fit on a single replica group? e.g. millions of objects you need to “shard” across many “replica groups”
conclusion Chain Replication is one of the clearest descriptions of a ROWA scheme it does a good job of balancing work it has a simple approach to re-syncing replicas after a failure influential: used in EBS, Ceph, Parameter Server, COPS, FAWN. it’s one of a number of designs (p/b, quorums) with different properties