Regularization
Overfitting
![]()
좋은 모델의 조건
- 학습 데이터를 잘 설명하는 모델
- 미래 데이터 또한 잘 예측하는 모델
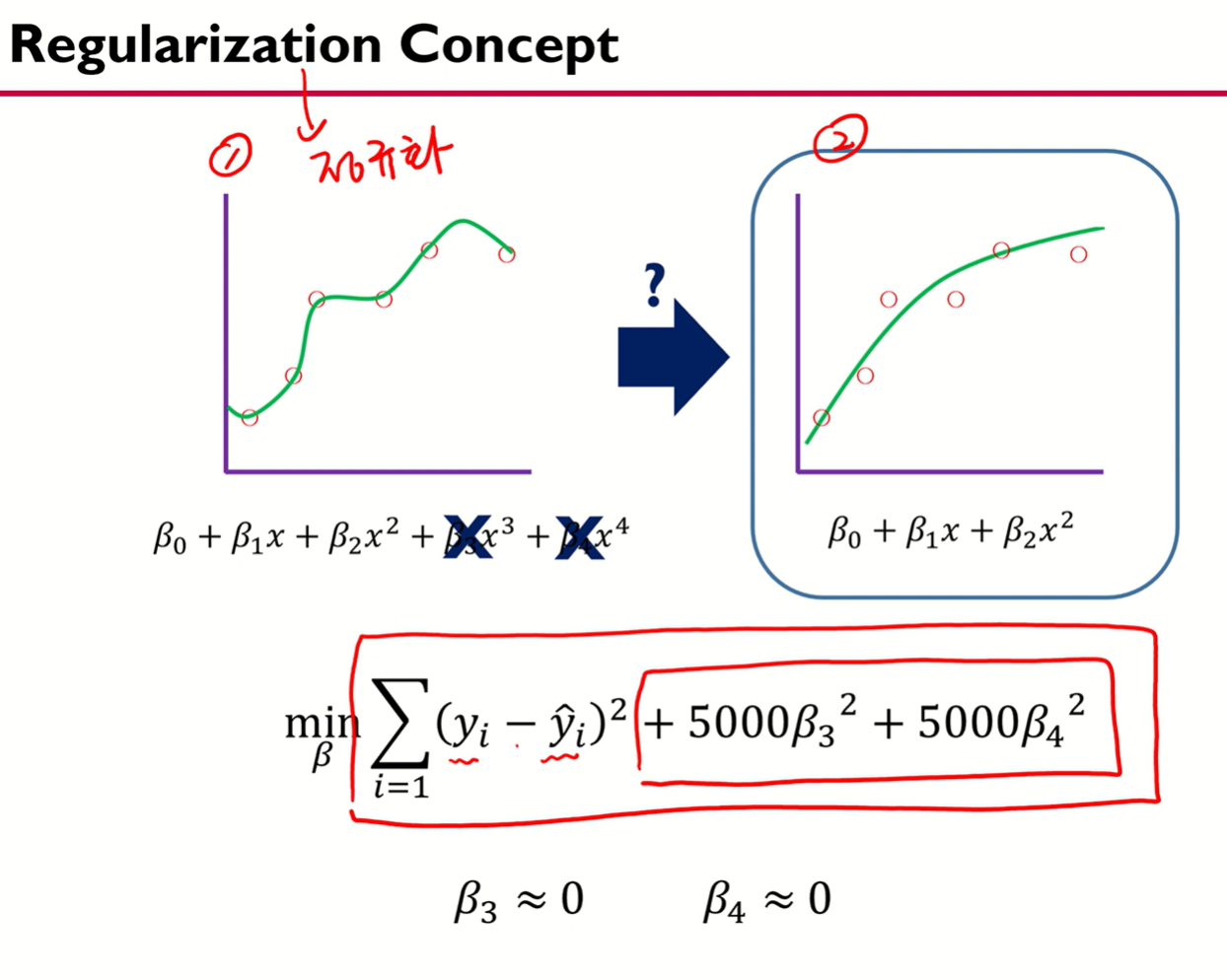
만약 위 사진처럼 과적합이 된다면
- 학습 데이터를 잘 설명하지만 실제 데이터에서는 오차가 증가하게 된다.
고로 generalization이 필요하다.
Concept
어떻게 규제할 것인가?
![]()
https://www.youtube.com/watch?v=pJCcGK5omhE&t=21s 출처
이유
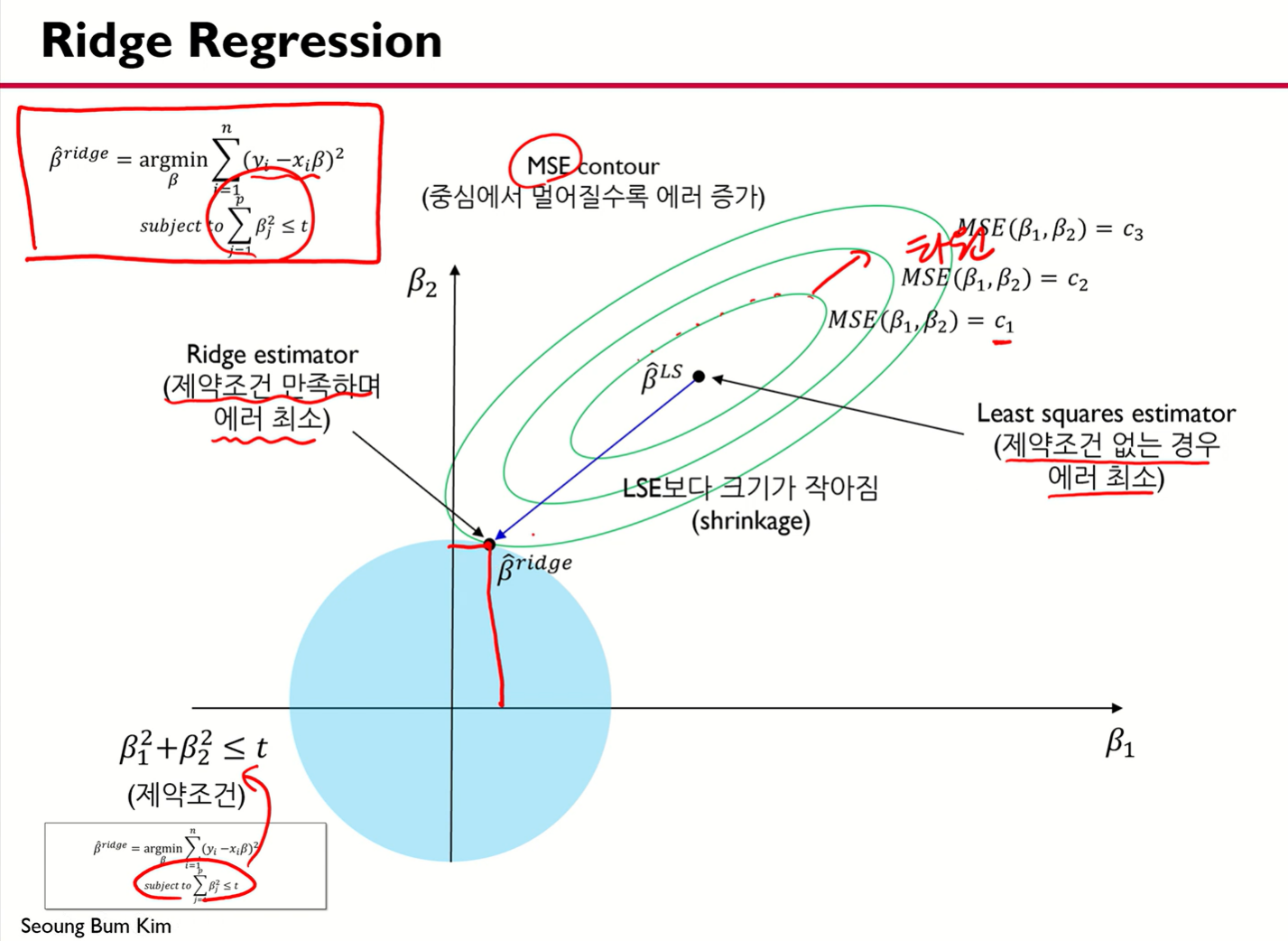
Ridge Regression
wmin21∣∣y−ϕ⊤w∣∣22 , s.t ∣∣w∣∣22 ≤B
Sol
- 이를 풀어내려면 Lagrange form으로 나타내야 한다.
Lagrange Multiplier Method 는 제약식이 있는 최적화 문제를 푸는 방법이다.
Lagrange Multiplier를 식에 더해 제약이 없는 문제로 바꿀 수 있다.
Lp=(y−ϕ⊤w)⊤(y−ϕ⊤w)+λ(∣∣w∣∣22−B)
Lp : Lagrange primal function
λ(∣∣w∣∣22−B) : regularizer
∂w∂[(y−ϕ⊤w)⊤(y−ϕ⊤w)+λ(∣∣w∣∣22−B)]=0
wLS=(ϕϕ⊤+λIn)−1ϕy
I : Identity matrix
특징
- λ의 값에 따라 w 값이 변한다.
- λ를 shrinkage parameter라고 부른다.
- λ가 0이면 규제가 없는 상태다.
- λ가 무한에 가까워지면 w값은 0에 근사한다.
![]()
https://www.youtube.com/watch?v=pJCcGK5omhE&t=21s
Rasso Regression
wmin21∣∣y−ϕ⊤w∣∣22 , s.t ∣w∣ ≤B
Sol
- Lagrange primal function 형태로 나타내자.
Lp=(y−ϕ⊤w)⊤(y−ϕ⊤w)+λ(∣w∣−B)
wargmin[(y−ϕ⊤w)⊤(y−ϕ⊤w)+λ(∣w∣−B)]
- w의 추청 값을 구하는 정규 방정식은 존재하지 않는다.
- w 값이 1이상이면 미분 불가능하다.
특징
- 어떤 관점에서 라쏘는 변수 선택에 사용된다.
- 다음 그림에서 보이듯 L1-norm 에서 축이 0이 된다.
![]()